
Quería saber cuánto me costaba cada sesión de Claude Code, qué modelos consumían más tokens, y cuánto tiempo pasaba bloqueado esperando que yo aprobara un tool call. La respuesta estaba en las variables de entorno OTEL_EXPORTER_* que Claude Code soporta desde hace poco. Lo que no estaba documentado en ningún lado eran los 5 problemas que tuve que resolver para que los datos llegaran a mi stack.
Este artículo documenta el pipeline completo, desde las env vars de Claude Code hasta un dashboard en Grafana con 34 paneles funcionando. Todo corre en un homelab con Kubernetes (Talos Linux), ArgoCD, Mimir, Tempo y un OTel Collector.
Qué emite Claude Code#
Primero lo primero: qué datos salen.
Métricas (3)#
| Métrica | Labels | Qué mide |
|---|---|---|
claude_code.cost.usage | model | Costo estimado en USD por operación |
claude_code.token.usage | model, type | Tokens consumidos (input, output, cacheRead, cacheCreation) |
claude_code.active_time.total | (sin label de model) | Tiempo activo acumulado en segundos |
Traces (5 tipos de span)#
| Span | Atributos clave |
|---|---|
claude_code.interaction | Span raíz de cada interacción |
claude_code.llm_request | model, input_tokens, output_tokens, cache_read_tokens, duration_ms, ttft_ms, stop_reason |
claude_code.tool | tool_name |
claude_code.tool.execution | success, duration_ms |
claude_code.tool.blocked_on_user | Tiempo esperando aprobación humana |
Con esto alcanza para armar un dashboard completo: costo, tokens, latencia por modelo, herramientas más usadas, tasa de error, y un explorador de traces.
La arquitectura#
graph LR
CC[Claude Code] -->|OTLP gRPC :4317| OC[OTel Collector]
OC -->|OTLP HTTP| Mimir[Mimir]
OC -->|OTLP gRPC| Tempo[Tempo]
Tempo -->|remote_write| Mimir
Mimir --> Grafana
Tempo --> Grafana
El OTel Collector corre como DaemonSet en el cluster. Recibe OTLP por gRPC, procesa las métricas con dos processors custom que explico abajo, y las manda a Mimir. Los traces van a Tempo, que además genera span-metrics y las escribe en Mimir vía remote_write.
Las env vars de Claude Code#
Configuración mínima para que Claude Code envíe telemetría:
export OTEL_EXPORTER_OTLP_ENDPOINT="https://otel-collector.elposhox.dev:4317"
export OTEL_EXPORTER_OTLP_PROTOCOL="grpc"
export OTEL_TRACES_EXPORTER="otlp"
export OTEL_METRICS_EXPORTER="otlp"Las pongo en ~/.zshrc para que estén siempre activas. Hasta aquí todo bien, pero el primer gotcha está a la vuelta de la esquina.
Problema 1: Claude Code stripea OTEL_* de child processes#
Si corres env | grep OTEL dentro del Bash tool de Claude Code, no sale nada. Claude Code elimina todas las variables OTEL_* de los procesos hijo por diseño, para evitar que herramientas internas contaminen la telemetría.
En la práctica, no puedes verificar la configuración OTEL desde dentro de Claude Code. Tienes que confiar en que las vars existen en el shell padre y verificar desde el lado del collector (logs del OTel Collector o métricas llegando a Mimir).
No hay fix. Es intencional. Solo hay que saberlo para no perder tiempo debuggeando fantasmas.
Problema 2: Delta vs Cumulative, Mimir rechaza con HTTP 400#
Claude Code envía métricas con temporalidad delta (cada data point es el incremento desde el último envío). Mimir requiere temporalidad cumulative (cada data point es el total acumulado).
El síntoma: el OTel Collector logueaba éxitos, pero Mimir respondía HTTP 400 con invalid temporality and type combination. Nada llegaba a Grafana.
El fix es el processor deltatocumulative en el OTel Collector:
processors:
deltatocumulative:
service:
pipelines:
metrics:
processors:
- memory_limiter
- resourcedetection
- attributes
- transform/claude
- deltatocumulative # antes de batch
- batchEl orden importa: deltatocumulative va antes de batch y después de cualquier transformación de labels.
Problema 3: Labels OTEL vs schema propio#
Yo tenía datos históricos de Claude Code metidos por un backfill script con labels normalizados: token_type=cache_read, token_type=cache_create. Pero Claude Code envía por OTEL: type=cacheRead, type=cacheCreation.
Dos esquemas distintos para lo mismo. Las queries de Grafana no podían cubrir ambos sin un {token_type=~"cache_read|cacheRead"} asqueroso.
El fix: normalizar al momento de ingestión con un transform/claude processor:
processors:
transform/claude:
metric_statements:
- context: datapoint
statements:
- set(attributes["token_type"], attributes["type"]) where attributes["type"] != nil
- replace_pattern(attributes["token_type"], "^cacheRead$", "cache_read")
- replace_pattern(attributes["token_type"], "^cacheCreation$", "cache_create")
- delete_key(attributes, "type") where attributes["token_type"] != nilCopia type a token_type, normaliza los valores de camelCase a snake_case, y elimina el label original. Después de esto, datos históricos y real-time usan el mismo esquema.
Problema 4: Tempo span-metrics no se generan#
Quería paneles de latencia por modelo, herramientas más usadas, y tasa de error, todo derivado de traces. Tempo puede generar estas métricas automáticamente con su span-metrics processor y escribirlas en Mimir.
Configuré el processor en values.yaml de Tempo:
metricsGenerator:
enabled: true
remoteWriteUrl: "http://mimir-gateway.mimir.svc.cluster.local/api/v1/push"
processor:
span_metrics:
dimensions:
- model
- tool_name
- successSync con ArgoCD. Nada. Las métricas traces_spanmetrics_latency_bucket y traces_spanmetrics_calls_total no aparecían en Mimir.
Lo que faltaba: activar los processors en la sección overrides. Sin esto, el distributor de Tempo recibe los traces pero no los rutea al metrics-generator:
overrides:
defaults:
metrics_generator:
processors:
- span-metrics
- local-blocksLa documentación de Tempo menciona metricsGenerator.enabled: true pero no enfatiza que overrides.defaults.metrics_generator.processors es obligatorio. Sin las dos cosas juntas, no pasa nada. Sin error, sin warning. Silencio total.
Problema 5: Dashboard que muere con el pod#
El dashboard de Grafana vivía solo en su base de datos interna. Si el pod moría, se llevaba el dashboard.
El fix: exportar el JSON y meterlo en un ConfigMap con el label que el sidecar de Grafana busca:
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-dashboard-claude-code
labels:
grafana_dashboard: "1"
annotations:
grafana_folder: "Claude Code"
data:
claude-code.json: |
{ ... dashboard JSON ... }El sidecar detecta cualquier ConfigMap con grafana_dashboard: "1" en cualquier namespace y lo carga solo. Si Grafana reinicia, re-carga todo desde los ConfigMaps.
Para mantenerlo actualizado, un script de 30 líneas (sync-dashboard.sh) exporta el JSON desde la API de Grafana y regenera el ConfigMap:
GRAFANA_USER=admin GRAFANA_PASS='...' ./sync-dashboard.sh
git add . && git commit -m "update dashboard" && git push
# ArgoCD sync > ConfigMap actualizado > sidecar recarga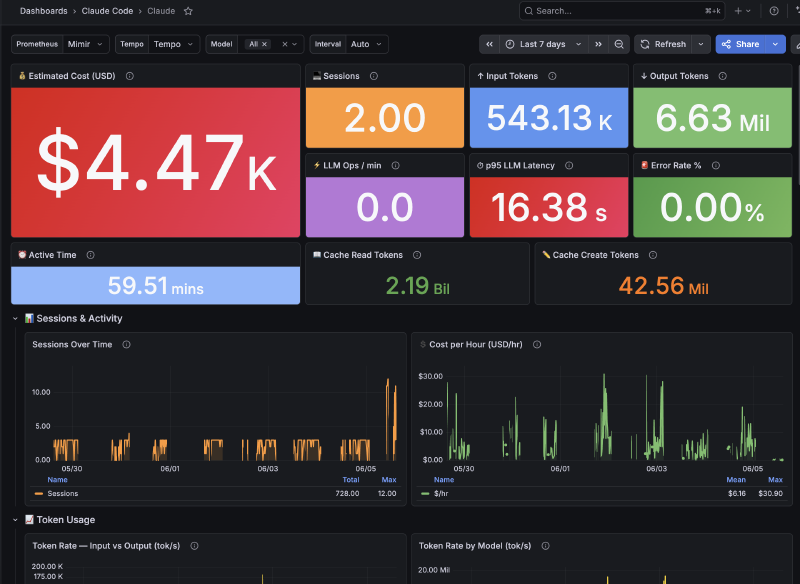
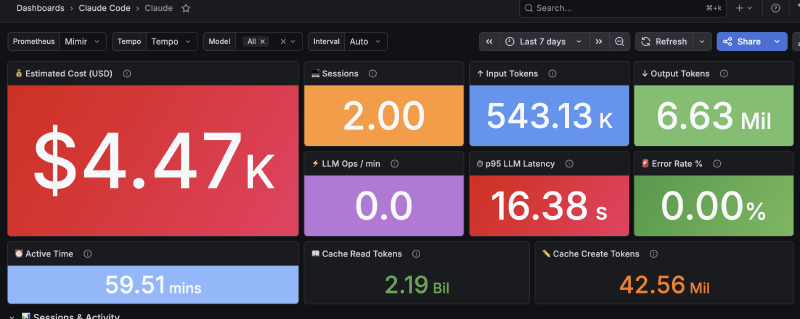
El dashboard: 34 paneles#
El resultado final tiene 34 paneles organizados en secciones:
Overview: Costo total, tokens totales, sesiones, LLM ops/min, error rate, p95 latencia
Tokens: Input vs Output over time, Token Rate by Model
LLM Performance: Latencia p50/p95/p99, latencia por modelo, heatmap de latencia
Tools: Calls by type, duración promedio por herramienta, errores de herramientas
Operations: Operaciones por modelo, distribución de modelos, sesiones over time
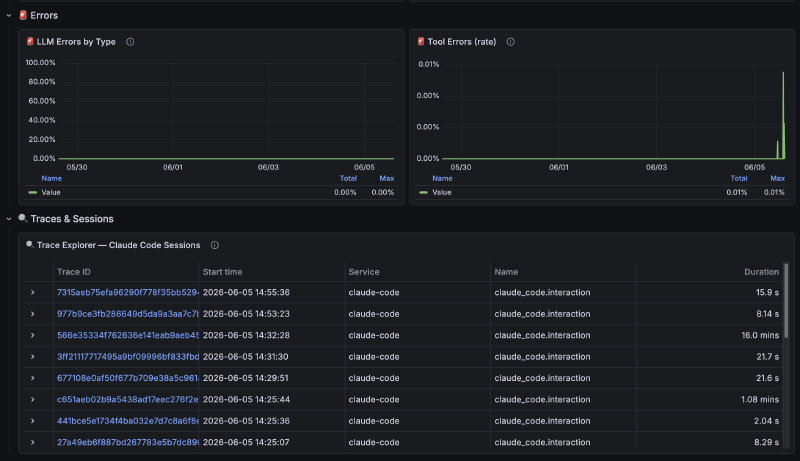
Trace Explorer: Tabla con traces de Tempo, click para ver spans completos
Las queries combinan datos de dos fuentes:
- Métricas directas (del OTel Collector a Mimir):
claude_code_cost_usage,claude_code_token_usage,claude_code_active_time_total - Span-metrics (de Tempo a Mimir):
traces_spanmetrics_latency_bucket,traces_spanmetrics_calls_total
Qué aprendí#
Lo que jala bien#
- El pipeline es estable. Resuelves los 5 problemas una vez y los datos fluyen sin tocar nada más.
- Span-metrics de Tempo te ahorran un chingo de trabajo. Latencia por modelo, tasa de error, tool calls, todo derivado de traces sin instrumentación extra.
- Dashboard-as-code con sidecar es el camino. Cero intervención manual post-deploy.
Lo que falta#
- Claude Code no emite logs por OTEL. Solo métricas y traces. Si quieres logs de las conversaciones, necesitas otro approach.
active_time.totalno tiene labelmodel, no puedes filtrar tiempo activo por modelo.- No hay forma de correlacionar una sesión de Claude Code con un commit o PR específico desde la telemetría.
¿Vale la pena?#
Si usas Claude Code diario y te importa saber cuánto gastas, qué modelo rinde mejor, o dónde se va el tiempo, sí. El setup toma unas 2 horas contando los gotchas que documenté aquí. Después no le vuelves a meter mano.