
Dos patterns, cada uno con su lugar#
Si corres servicios en EKS que necesitan tráfico público, tienes dos opciones de arquitectura:
Pattern A: ALB público + WAF regional. El ALB tiene IP pública, WAF se asocia directo al ALB, el tráfico llega sin intermediarios. Esto funciona y es necesario para gRPC (WAF ignora body inspection en gRPC sobre CloudFront), WebSockets con idle mayor a 10 minutos (hard limit de CloudFront, no configurable), y APIs con response times mayores a 180 segundos.
Pattern B: CloudFront + VPC Origin + WAF. El ALB es privado, CloudFront es el único punto de entrada, WAF se asocia a CloudFront (scope global, siempre us-east-1). Este es el pattern para HTTP/HTTPS público estándar.
En este artículo cubriremos el Pattern B, si tu servicio usa gRPC o WebSockets de larga duración, el Pattern A sigue siendo el correcto, aunque para WebSockets podrías usar el B con un mecanismo de Keep Alive.
El flujo de red completo#
flowchart TD
Client["Cliente"] --> DNS["DNS (Route53)
CNAME → CloudFront"]
DNS --> CF["CloudFront
HTTPS termination"]
CF --> WAF["AWS WAF
Web ACL"]
WAF --> VPC["VPC Origin
AWS Backbone"]
VPC --> ALB["ALB (privado)
internal scheme"]
ALB --> Pod["EKS Pod"]

El flujo es simple, el request entra por CloudFront, que termina TLS, después el WAF evalúa el request contra las reglas del Web ACL. Si pasa, CloudFront lo envía al ALB via VPC Origin, que usa la red backbone de AWS (nunca sale a internet) hasta el ALB que es internal… Sin IP pública, sin acceso directo desde internet.
Por qué VPC Origin y no ALB público#
Antes de VPC Origins (noviembre 2024), la arquitectura era: ALB público + CloudFront enfrente + WAF en CloudFront, el problema era que el ALB tenía IP pública. Cualquiera que descubriera el dominio del ALB podía pegarle directo, saltándose CloudFront y WAF por completo.
Las mitigaciones pre-VPC Origins eran parciales:
Prefix list de CloudFront en security groups. AWS publicó un managed prefix list (
com.amazonaws.global.cloudfront.origin-facing) en febrero 2022. Restringe el SG del ALB a IPs de CloudFront. El problema era que cualquier persona puede crear una distribución de CloudFront, el prefix list asegura que el tráfico viene de algún CloudFront, no de tu CloudFront.Custom headers (X-Origin-Verify). CloudFront agrega un header secreto, el ALB lo valida. Funciona sin duda, pero requiere enforcement a nivel de aplicación y rotar el secreto.
VPC Origin elimina el problema de raíz: el ALB está en subnet privada, no tiene IP pública y solo es alcanzable desde la distribución de CloudFront del mismo account de AWS. No hay bypass posible.
La cadena de evaluación del WAF#
Esta es la parte que la documentación de AWS no explica bien en un solo lugar, el Web ACL evalúa reglas en orden de prioridad numérica (menor = primero), para ello hay dos tipos de acciones:
- Terminating (Allow, Block): detiene la evaluación
- Non-terminating (Count): agrega labels al request y continúa la evaluación
Los labels son visibles para todas las reglas subsecuentes en el mismo Web ACL, esto permite evaluación en múltiples pasos: etiqueta en una regla, matchea el label en otra.
Nuestro orden de evaluación#
flowchart TB
R1["Priority 1-N
RuleGroup shards
COUNT + label
custom:tekal:host-allowed"] --> R2["Priority 5
block-unknown-hosts
BLOCK si no tiene label"]
R2 --> R3["Priority 10-60
AWS Managed Rules
SQLi, XSS, Bot Control"]
R3 --> R4["Priority 70
Rate Limit
BLOCK > 2000 req/5min"]
R4 --> R5["Priority 99
allow-valid-traffic
ALLOW si tiene label"]
R5 --> R6["Default Action
BLOCK"]
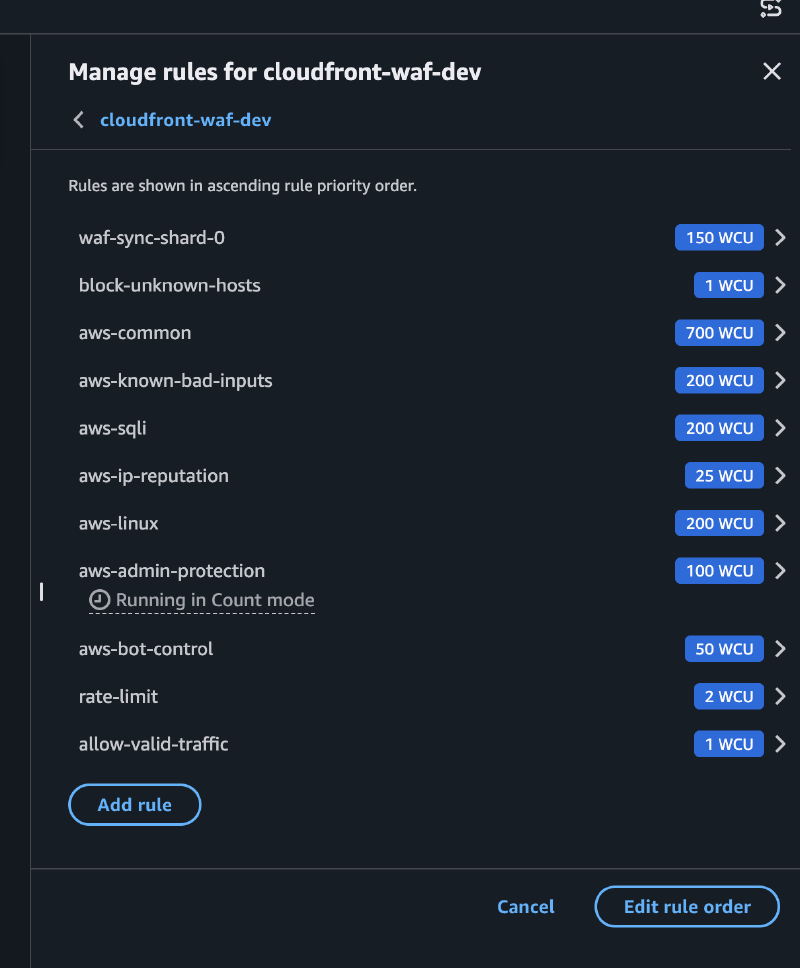
Priority 1-N: RuleGroup shards#
Cada hostname válido tiene una regla ByteMatch que compara el header Host, si matchea, la regla usa COUNT (non-terminating) y agrega el label custom:tekal:host-allowed, el request sigue evaluándose.
Priority 5: block-unknown-hosts#
Si el request NO tiene el label custom:tekal:host-allowed, se bloquea. Hosts desconocidos mueren aquí, antes de gastar WCUs en managed rules.
Priority 10-60: AWS Managed Rules#
SQLi, XSS, Bot Control, etc, solo evalúan tráfico con host válido, un atacante mandando requests con host inventado no consume WCUs de estas reglas.
Priority 70: Rate limiting#
BLOCK si excede 2000 requests por 5 minutos.
Priority 99: allow-valid-traffic#
Si el request llegó hasta aquí con el label, se permite explícitamente.
Default action: BLOCK#
Todo lo que no fue permitido explícitamente se bloquea.
¿Por qué COUNT y no ALLOW?#
Si usaras ALLOW en las reglas de hostname (priority 1-N), el request se aprobaría inmediatamente, las managed rules en priority 10-60 nunca se evaluarían. Un atacante con un hostname válido podría mandar SQL injection y pasaría directo.
COUNT es non-terminating, etiqueta el request como “host conocido” y deja que las managed rules lo evalúen. ALLOW solo se usa al final (priority 99), después de que todas las protecciones se aplicaron.
El gotcha de label namespacing#
Los labels de un RuleGroup aparecen namespaced en el Web ACL:
awswaf:<account_id>:rulegroup:<name>:custom:tekal:host-allowedcustom:tekal:host-allowed solo funciona dentro del mismo RuleGroup, desde el Web ACL (donde vive block-unknown-hosts), tienes que usar el key full-qualified. Con N shards necesitas un or_statement con un label_match_statement por shard, esto es porque AWS WAF rechaza or_statement con un solo elemento, así que con 1 shard tenemos que usar label_match_statement directo.
En HCL esto se resuelve con jsondecode(jsonencode(...)) para manejar el conditional con tipos diferentes.
El exposure model en el Helm chart#
Para que los equipos de aplicación no tengan que pensar en esto, el chart de nuestra plataforma e IDP (Tekal) tiene un campo networking.exposure con tres modos:
| Modo | ALB Scheme | DNS apunta a | Uso |
|---|---|---|---|
private (default) | internal | ALB | Servicios internos |
cloudfront | internal | CloudFront | Servicios públicos con WAF |
public | internet-facing | ALB | Casos excepcionales sin CloudFront |
Con exposure: cloudfront, el chart genera un Ingress con la annotation external-dns.alpha.kubernetes.io/target apuntando al dominio de CloudFront, el DNS (via external-dns) crea un CNAME al CloudFront en vez del ALB mientras que el ALB se mantiene privado.
El cloudfrontDomain se inyecta a nivel de ApplicationSet per environment. Los equipos de aplicación solo eligen cloudfront y la plataforma se encarga del resto, esto para siempre darle prioridad el DevEx.
Multi-region sin cambiar código#
Cuando necesitamos dos regiones de producción (us-east-2 para tráfico US, ca-central-1 para tráfico canadiense), el primer instinto es compartir la distribución de CloudFront, lo cual a mi parecer era mala idea para nuestro enfoque.
El controller de WAF (tekal-waf-sync) hace full-replace de todas las reglas en cada reconciliación, dos controllers escribiendo a los mismos RuleGroups crea un ping-pong destructivo:
t=0 controller-us reconcilia -> WAF = [api.example.com]
t=1 controller-ca reconcilia -> WAF = [api.example.ca] <- hostnames US borrados
t=2 controller-us reconcilia -> WAF = [api.example.com] <- hostnames CA borradosLa solución: una distribución de CloudFront por dominio donde cada dominio tiene su propia distribución, su propio Web ACL, y sus propios RuleGroups. Cada controller maneja sus propios RuleGroups, cero conflicto, cero cambios de código.
| Config | prd-us | prd-ca |
|---|---|---|
| WAF_SCOPE | CLOUDFRONT | CLOUDFRONT |
| WAF_REGION | us-east-1 | us-east-1 (WAF CF siempre global) |
| CLOUDFRONT_TARGET | d111.cloudfront.net | d222.cloudfront.net |
| DOMAIN_SUFFIX | example.com | example.ca |
Los beneficios de este enfoque son:
- Blast radius completamente aislado: Si CF-CA tiene un problema, CF-US no se entera.
- Compliance PHIPA: el origin está en ca-central-1, los datos canadienses nunca se procesan fuera de Canadá.
Agregar una tercera región (EU, GDPR) = nueva distribución + nuevo Web ACL + nuevos RuleGroups + nuevo deployment del controller… Config, no código.
Gotchas que costaron tiempo#
Empty InsertHeaders,
CustomRequestHandling.InsertHeaders: [](lista vacía) es rechazado por AWS WAF. El error es genérico, no indica qué campo falló, omite el campo entero si no necesitas headers custom.Pod Identity bloquea todo HTTPS. El Pod Identity agent intercepta todo el tráfico HTTPS del pod. Si el ServiceAccount no matchea la association, bloquea todo, incluyendo acceso al API server de Kubernetes, el controller falla con connection timeouts, no con errores de auth. El síntoma parece un problema de red, no de IAM.
CPU limits de 10m causan lease timeout. Controller-runtime leader election renueva lease via HTTPS, 10m de CPU limit es insuficiente para el burst del TLS handshake. Lease renewal timeout, el leader baja, restart loop infinito. Mínimo 50m.
WAF_REGION separado de AWS_REGION. CloudFront WAF vive en us-east-1 globalmente, pero el controller corre en us-east-2 (donde está el cluster), se usaron env vars separadas:
AWS_REGION=us-east-2(cluster, Pod Identity) yWAF_REGION=us-east-1(WAF API). Si usasAWS_REGIONpara ambos, Pod Identity falla o WAF API no resuelve.
El problema que queda#
La lista de hostnames en WAF debe reflejar exactamente los Ingresses que existen en el cluster. Si agregas un servicio y no actualizas WAF, block-unknown-hosts mata tu tráfico legítimo. Si decomisionas un servicio y no limpias WAF, tienes un hostname fantasma.
Mantener esa lista a mano funciona con 5 servicios, desde CI pipeline funciona hasta que alguien hace un kubectl edit en una emergencia o ArgoCD hace un rollback que cambia hostnames, el estado real del cluster y la lista de WAF divergen silenciosamente.
El siguiente artículo cubre cómo resolvemos esto con un controller que hace watch sobre Ingresses y sincroniza el WAF Group Rule automáticamente, el mismo patrón que external-dns usa para DNS.